Systemic Shortsightedness
How Short-Term Focus Creates Long-Term Problems
In high-pressure environments, engineering organizations often drift into reactive patterns that sacrifice long-term resilience for short-term delivery. This article explores how threat rigidity, centralized control, and eroded trust contribute to burnout, architectural fragility, and systemic failure. Drawing from real-world examples, it illustrates how short-term wins can mask deeper issues—and how unchecked attrition, fragile systems, and deferred improvement compound over time. But it also offers a path forward: by focusing on trust, sustainable work, and technical excellence, leaders and engineers alike can reshape the systems they operate in and build resilient organizations that endure.
Reflecting on a Decade of Engineering
Over the past decade, I’ve seen a recurring pattern emerge in engineering organizations: when under pressure (or perceived pressure), systems tend to respond in surprisingly consistent ways. Organizations tend to become more reactionary, leaders centralize control, and teams become more focused on delivery of short-term results over long-term sustainability.
Burnout stems from disconnects between the individual and the organization across several dimensions: workload, community, reward, values, and more. But when we examine the systemic causes of these factors, we often find deeper management issues at play.
My aim isn’t to make broad generalizations, but to surface common patterns—especially those that create long-term risks masked by short-term signals of success.
What is Threat Rigidity?
Threat rigidity is a well-documented organizational response to perceived existential threats. It defines a behavioral model where organizations under stress become more rigid and less adaptive.
These threats can be real or perceived, and can come from a variety of sources such as new market competitors, changing economic circumstances, or internal changes like layoffs and reorganizations.
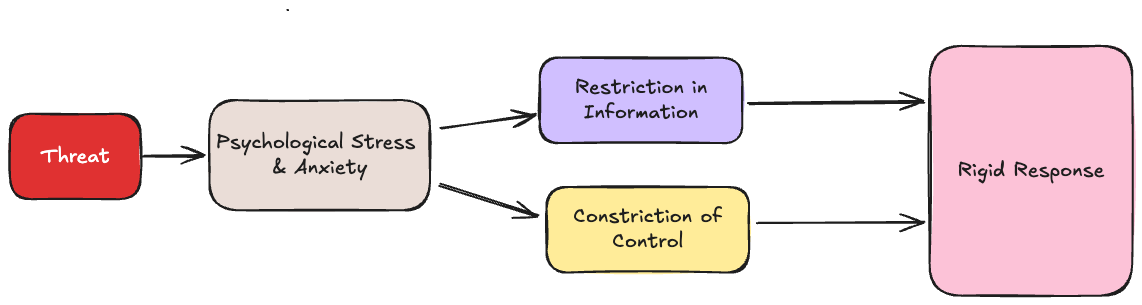
The stress response creates a restriction in information processing causing individuals to rely on internal hypotheses and focus only on dominant external signals and constriction in control driving individuals towards well-learned responses with increased drive.
In engineering organizations, this looks like:
- High delivery pressure with short time scales
- Shortened planning horizons (e.g. 1-2 weeks)
- Over-reliance on demos to demonstrate progress
- Reduced autonomy and learning
Imagine you're the CEO of a company. You’ve just faced a sudden decrease in quarterly stock price. As CEO, the majority of your compensation package is tied directly to the stock price. Worse, if this continues, you won't be CEO for much longer. You’re under substantial pressure to make decisions that will stabilize the company and restore investor confidence quickly.
Threat Rigidity in Engineering
Over time temporary coping mechanisms can become cultural defaults. As reactionary firefighting becomes the norm, the system begins to reward behaviors that prioritize short-term results over long-term sustainability.
In such environments, design thinking and reflection are deferred in favor of immediately visible deliverables. Often framed as a form "resilience" or "agility", this shift is a symptom of an inability to adapt to changing conditions.
Similarly, decisions which should be informed by diverse perspectives or delegated to the people with the most direct knowledge, become more centralized and escalated to more senior leadership, limiting insights into long-term consequences.
Narrowing of Focus
Tunnel vision is a common response to stress. Leaders begin to optimize for the most immediate and measurable outcomes. This causes leaders to perpetuate a narrative that "we just need to hit the next milestone". Without a broader strategic perspective, “crunch mode” becomes the new norm—this creates a cycle where short-term wins become the default target.
Teams prioritize high-visibility features over all else. Planning, design, operational excellence, infrastructure improvements, and maintainability— anything not visible to leadership or stakeholders in the next sprint or two— is deprioritized or deferred.
While this narrowing can feel productive in the moment, it often comes at the long-term cost of system maintainability. This long-term cost will eventually make it harder and harder to make changes to the system.
The result is a local optimization loop that reinforces itself: we meet the metric, so we do more of the same—even if it’s misaligned with our real goals.
Centralization of Control
The threat rigidity model describes a constriction of control—that is, decision-making authority tends to centralize. Leaders, feeling accountable for outcomes, often pull decisions upward. Decisions once made by teams or individuals are now made by directors and VPs. This often begins as an effort to improve coordination and ensure alignment, but as the system becomes more rigid, it leads to a centralization of control.
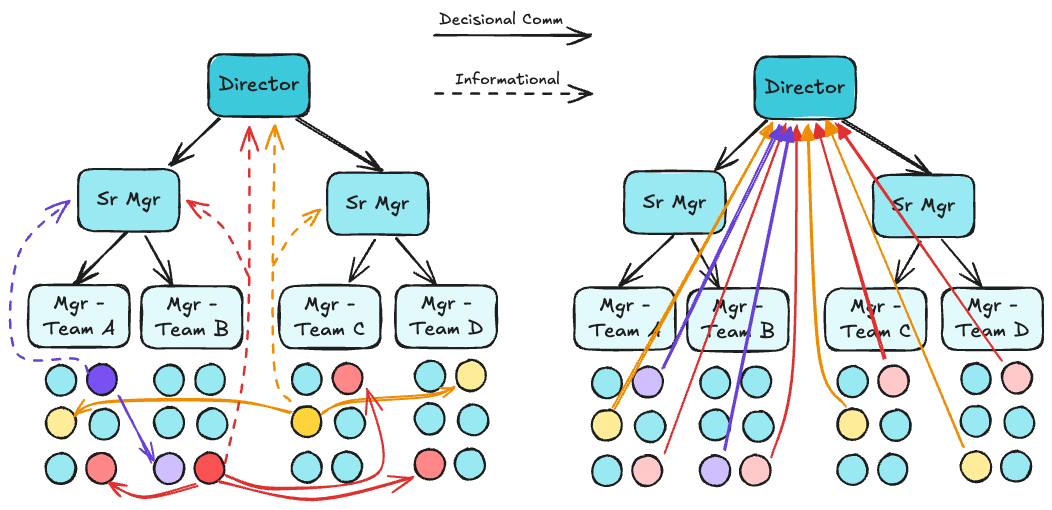
Leaders may find themselves making decisions without the context or expertise of those closest to the work. This can lead to poor decision-making and a lack of ownership among teams. Meanwhile, engineers may find themselves with less autonomy. From the teams' perspective, this feels a lot like micromanagement. This can erode trust, undermine psychological safety, and reduce motivation; the quality of decisions made is ultimately degraded.
This shift isn't always framed as control; it may be positioned as "alignment", "urgency", or "risk reduction". But the underlying pattern is consistent: the system begins to treat deviation as a threat. Management will tend to require more frequent status updates and expect teams to justify or get approval for every small decision.
Deferred Improvement
The narrowing of focus and centralization of control create a negative feedback loop that deprioritizes strategic long-term objectives. Even when teams know what’s needed—better operational excellence, critical enablers, revisiting architectural decisions—they’re discouraged from doing so unless it directly ties to a deliverable. Some patterns include:
- Retrospectives become rushed or skipped entirely
- Design reviews are shallow, ignored, or held too late
- Learning, training, and knowledge-sharing activities are deprioritized
- Postmortems focus on blame or quick fixes, rather than deep root cause analysis and long-term solutions
This sort of deferred experimentation and learning is common when the organization creates this sort of negative feedback loop. This further reinforces the "just get it done" culture, where the focus is on shipping features at the expense of quality. Testability, maintainability, and operational excellence are thrown out the window.
The system stops making time for structured improvement and adaptation— often because these activities are seen as non-essential compared to visible delivery work. But without them, small problems compound and the system begins to fray. Over time, the absence of deliberate improvement becomes a primary driver of fragility as teams lose the context they need to make good decisions.
Short-Term Gains, Long-Term Losses
From a control systems perspective, we can be viewed as a poorly tuned feedback loop. Leaders react to lagging indicators (e.g., missed deadlines, stakeholder dissatisfaction) with short-term corrections without accounting for the long-term cause and effect.
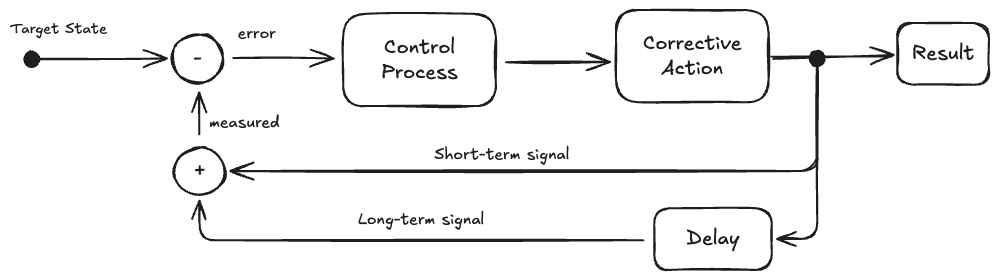
These corrective actions generate immediate output signals: features are shipped, stakeholders are happy, (certain) metrics trend in the right direction. These signals reinforce the actions. But the delayed negative feedback — degraded architecture, attrition, and eroded trust — is filtered out or too significantly delayed. The system lacks awareness of long-term signal trends.
| Action | Short-Term Signal | Long-Term Cost (Delayed Signal) |
|---|---|---|
| Overwork team to hit deadline | Project ships, happy leadership | Churn, reduced trust, rising cynicism |
| Push out dissenting employees | "No complainers left," less friction | Groupthink, loss of challenge and ideas |
| Deliverables over all else | Demos look great, short-term KPIs met | Mounting tech debt, future velocity collapse |
| Define high performance narrowly | Visible output from a few individuals | Underutilized talent, burnout, cultural distortion |
The result is an organizational control loop that is over-reliant on high-gain short-term signals and underweights lagging long-term health indicators. Over time, the system becomes unstable—not because no one is steering, but because the signals being amplified are the wrong ones.
Healthy organizations recognize when their feedback loops are amplifying the wrong signals—and redesign them before the system fails.
Building Trust
Psychological Safety
Psychological safety is the "shared belief held by members of a team that the team is safe for interpersonal risk taking". In their study on team effectiveness, Google found that psychological safety was the most important factor contributing to building high-performing teams.
In his book The Culture Code, Daniel Coyle not only describes psychological safety as the foundation of a healthy high-performing team culture. He focuses on belonging cues and demonstrating vulnerability — trust-building behaviors demonstrated by leaders in high-performing teams across a range of fields.
The common denominator in each of these is that teams with high psychological safety are more likely to take interpersonal risks, share ideas, and collaborate effectively.
There are many signals of an absence of psychological safety in an organization, including:
- Fear of speaking up; No one pushes back on unrealistic plans
- Retrospectives are performative
- Decisions are made without dissent
Leaders can shift this dynamic by modeling vulnerability, inviting challenge, and reinforcing through actions—not just words—that it’s safe to raise concerns, admit uncertainty, and share ideas.
Burnout Factors
Burnout isn’t just about long hours and hard work — it’s what happens when people operate in systems where the demands are high, but the conditions for healthy, sustainable work are missing. It can manifest physically (e.g. fatigue), emotionally (e.g. anxiety), behaviorally (e.g. cynicism, disengagement), and cognitively (e.g. lack of focus) (Kanojia).
Research identifies six key factors that drive burnout (Leiter & Maslach):
- Workload: Excessive workload, unrealistic deadlines, and lack of resources can lead to burnout.
- Control: Lack of autonomy and control over work can lead to feelings of helplessness and frustration.
- Reward: Lack of recognition and reward for hard work can lead to feelings of undervaluation and resentment.
- Community: Lack of support and connection with colleagues can lead to feelings of isolation and loneliness.
- Fairness: Perceptions of unfairness and inequity in the workplace can lead to feelings of resentment and frustration.
- Values: Misalignment between personal values and organizational values can lead to feelings of disconnection and disengagement.
When multiple factors are present—and when teams don’t feel safe speaking up about them—burnout becomes more than personal fatigue; it becomes a system-wide failure mode.
Burnout is not just an individual problem. It drives disengagement, weakens feedback loops, and gradually erodes the capacity for reflection and resilience. And when the system doesn't adjust, people leave—or worse, they stay and disconnect.
Attrition as System Drift
"Attrition is a healthy management practice. Those who can't hack it should leave. It makes the organization better."
This was said to me by a senior technical leader. It was a sentiment that wasn't an outlier — it was the common belief in the organization.
In this organization, a typical work week for me was 50-60 hours (and I was probably putting in the least effort of anyone on my team), on-call weeks were typically 80 hours or more, weekend work was the norm, deadlines were aggressive and unrealistic, scope of work was large, and when optimistic plans ran into unexpected issues, the engineers bore the consequences. Attrition was extraordinarily high.
The organization viewed the attrition as a sign that the organization was effectively filtering out those who weren't a good fit for their high-pressure environment. It was seen as a mechanism of natural selection—those who could not handle the pressure were simply not cut out for the organization.
Instead, the organization was creating a culture of fear and mistrust. Middle managers were afraid to speak up to senior leaders. Engineers who raised concerns about system quality or sustainability were labeled as "not team players".
As a result, system quality degraded. Documentation and playbooks were missing. Testing was limited or missing. Corners were cut in the name of feature delivery and design decisions were rushed without fully understanding the implications of certain decisions.
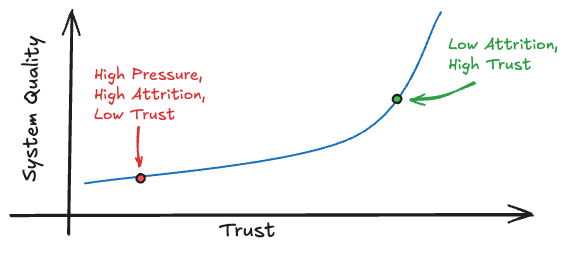
And while short-term output yielded highly visible results, the downstream consequences were very real. Pipelines would break downstream as teams integrated changes from one another, bugs made it into production as often as features, and outages in production happened every few weeks.
When skilled engineers advocating for operational excellence and sustainable development walk out the door, the system becomes more fragile, even if velocity appears unaffected in the short term. Teams become less able to adapt to changing conditions, and the system begins to experience failure modes.
Architectural Erosion
Architecture tends to decay under pressure—not because people forget design principles, but because they are denied the conditions required to practice them.
Systems Fail Under Pressure
Under pressure, even skilled teams begin to compromise. Design shortcuts, corner-cutting fixes, and deferred testing or design aren’t signs of incompetence — they’re a survival mechanism in an environment that rewards delivery over integrity. When delivery is rewarded and focus on quality at the expense of delivery timeline is penalized, tradeoffs will be made that conform to that environment.
On one project I worked on, a Java monolith used a shared mutable context object across the codebase to manage configuration and state. Bugs were often fixed with ad hoc mutations to this object, introducing subtle side effects elsewhere. Lack of contextual understanding, review processes, and testing let this team down an infinite reactionary loop of fixes that never addressed the root cause.
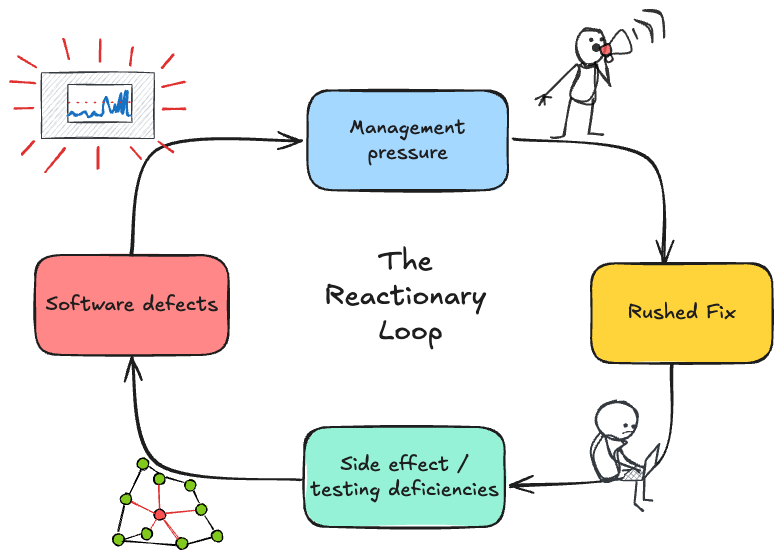
This created a common paradigm: bugs become visible and cause leaders to worry, leaders pressure engineering teams for fast fixes, engineers rush the fix under pressure, which introduces more problems, further exacerbating the cycle.
It's not unique to a given language, framework, or technology—it's a fundamental technical management problem. In one embedded Rust project, management pressure to deliver what engineers estimated to be several weeks to a couple months of work in only a few days, led to a bug that shipped to production causing a complete failure of the new feature on 13% of devices. What was most interesting in this case was that it wasn't due to lack of testing, but because the tests replicated the wrong assumptions. No one had the time or context to catch the issue in design or code review and sufficient hardware testing was skipped.
Tech Debt Accumulates
Critical services suffer most when continuity breaks. Fragility becomes systemic when teams can no longer reason about the systems they own.
One critical pservice experienced multiple production outages spanning hours at a time. In one case, this system leveraged deploy-time configuration code that was pulled from an external team and compiled on-the-fly at deploy time. This caused a production outage when that external code was changed without the team's knowledge. To make things worse, this caused rollbacks to fail because the issue happened at deploy time, not compile time.
The code deployment should never have worked this way. This was designed and implemented by a competent senior engineer under intense delivery pressure. It wasn't caught or seen as an issue in design or code review. Delivery was prioritized over risk. But the very nature of risk is that they have a probability of actually occurring.
But technical debt accumulates and is multiplied by attrition. Within a month of this incident, the last experienced engineers left that team, leaving behind a small handful of people who had joined the team less than three months prior.
So when the system again had a production outage, this time due to the use of dynamic IPs. The service's IP changed on redeployment, causing an outage for all clients, which used a hardcoded IP to connect to this service. When I asked why the service was using dynamic IPs in the first place, the response was "we don't know" and was directed to speak with someone no longer with the team.
These are only some examples of a system that had outages every few weeks. These outages were brushed under the rug to leadership, postmortems were skipped and dismissed as "a waste of time" and the system remains fragile.
A Problem for Later
Often times, these sort of technical quality risks are dismissed as a problem for another day. The consequences are too far off or too low likelihood to feel tangible.
On one team, a critical library lacked sufficient engineering resources to maintain it. Interfaces were poorly defined, documentation was sparse, and no branching strategy or release process was in place. Despite those risks, the team was pressured to deliver a feature that required changes to this library. Within 24 hours of the release, the team's on-call engineer was being paged. The change broke several downstream systems resulting in three alerts directly paging the on-call engineer and several more impacting other teams' on-call. The team had to roll back the change.
Even after this incident, the lack of release strategy wasn't addressed and the problem recurred multiple times over the following months.
A similar incident occurred when a technical leader asked an engineer to make a feature change and deliver it that same day. "It will only take an hour" the tech lead said. In practice, it took three. But the real problem occurred the following morning when customers identified that this caused a break in production. The on-call engineer and an engineer familiar with the system spent another hour trying to understand what happened before rolling back the change.
In order to test the feature, the code needed to be completely refactored for testability (another ramification of earlier delivery pressure). It took several weeks to perform the refactor and implement tests. Months later, the 1-hour feature request still wasn't delivered.
My point here is a simple one: consequences happened. Risks are real. Sometimes they manifest months or years down the road, sometimes it is days. But that debt accumulates. These examples come from an organization that had been operating with a deliver-over-quality culture for several years. These were the consequences.
Loss of Control
When institutional knowledge disappears and architectural qualities begin to erode, new architectural decisions degrade in quality and reversibility.
In these scenarios, teams don’t just lose momentum — they lose the ability to intervene safely. Refactors are too risky. Monitoring gaps go unaddressed. New features are bolted on as exceptions to the existing architectural decisions and conventions rather than cohesively integrated capabilities.
When teams can’t reason about the system, they can’t make changes safely. The system becomes increasingly fragile and, as fragility grows, trust declines. Process and control become a substitute for understanding and trust.
Leadership is Ownership
"The leader is responsible for everything the team does or fails to do."
Leadership is ownership—ownership of outcomes, of culture, and of the conditions team operates within. By taking on a leadership position, you are taking on responsibility.
A leader's job is to influence others. Influence, not demand. This is done by modeling the behavior you want to see in others—by leading by example.
It also means showing care and concern for those you lead. Leaders have significant influence over the conditions in which teams operate.
For example, imagine your boss asks you to work late to meet a deadline. They head out at 5pm and you are stuck working until 9pm to finish the work. Contrast this with a boss who stays late with you to help finish the work or the one who takes responsibility for the missed deadline and lets the team go home on time and finish up the work the next day. Which one would you rather work for?
Influence comes from trust. Trust is built through actions like this that build credible trust to the team.
Case Study: Incident Postmortems and Leadership Causes
Consider a post-mortem, where a team was asked to reflect on a system outage. The team identified the root cause as a lack of unit testing in the failed service. But that code was owned by one of our most experienced engineers—by far our strongest proponent of operational excellence.
A critical exercise during an incident post-mortem is to perform a 5 Whys analysis to identify the root cause of the incident. But in this case, the team stopped the analysis at "tests were missing". The root cause analysis should have continued along the following lines:
- "Why were the tests missing?" Because the engineer did not have time to write tests.
- Why didn't the engineer have time to write tests? Because the delivery deadline was too short for the scope of work.
- Why was the delivery deadline so short? Because the team was under pressure from management to deliver the feature by a given date.
- Why was management under pressure? Because managers didn't respect the team's original estimates and pushed for a faster delivery.
- Why didn't management respect the team's estimates? Because management didn't have an adequate understanding of the team's work or clear roles/responsibilities.
The problem here is two-fold: first, there was a major leadership failure that never entered the post-mortem discussion. Second, the team was placed in an environment where leaders made unrealistic demands and the engineering team was held responsible for the failure. In other words, if the team is successful, the leaders take credit. If the team fails, the leaders blame the team. This is the opposite of ownership on the leader's part.
Leadership begins with ownership. Leaders must take responsibility for the team's actions and decisions. They must create an environment where teams can thrive, where they can take risks, and where they can learn from their mistakes. This means creating a culture of trust, where team members feel safe to speak up, share ideas, and challenge the status quo.
Toward a Healthier System
All of these leads to the inevitable question: "How do we fix this?"
It begins with leadership. Leaders must take ownership of the systems they are responsible for. If the team succeeds, it will be in part because the leader enabled them to succeed. If the team fails, it is because the leader failed. Leaders must create an environment where teams can thrive.
Trust and psychological safety is the most important component of team building. Leaders must model vulnerability, invite challenge, and reinforce through actions that it's safe to raise problems without backlash.
Sustainable work is a non-negotiable condition for long-term team health. Strong technical project management skills are critical to ensuring that teams are committing to realistic plans and sustaining manageable workloads.
Technical excellence is a shared responsibility. Engineers must advocate for long-term system health and leaders must create the conditions for teams to do so. Cutting corners to meet short-term deadlines should be seen as a negative health signal and leaders must recognize that.
Teams must be empowered to make decisions and take ownership of their work. Either one alone is insufficient. When teams have responsibility without authority, they can't make the changes needed to ensure system success.
In the end, lasting success isn’t built on short-term wins. It’s built on systems—both technical systems and human systems—designed to learn, adapt, and endure. That starts with leadership. Not just taking credit when things go well, but owning the conditions that shape outcomes.
Build trust. Make sustainability non-negotiable. Invest in technical health. Empower your teams. If you fix the system, the results will follow.